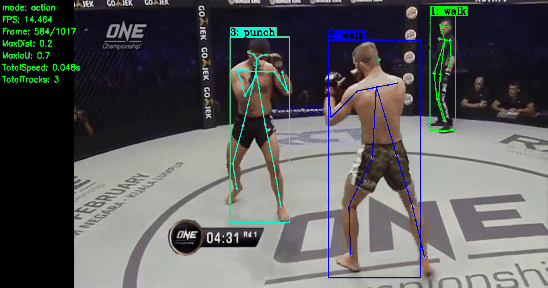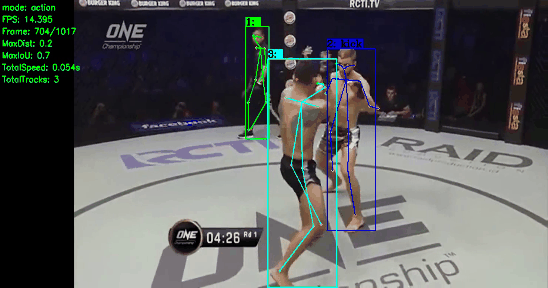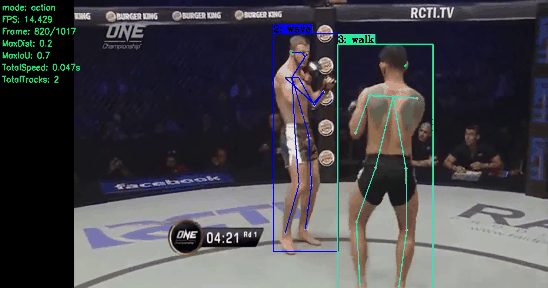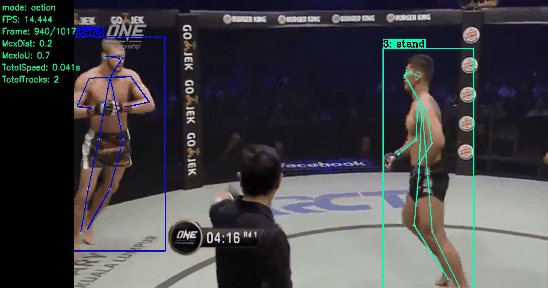
About Me

I have 3+ years of work experience in Computer Vision field and a Bachelor Degree in Electrical and Electronics.
I'm a self-taught, fast learner with good problem solving skill. I'm keen interested in building and training
SOTA deep learning models from scratch with custom datasets. I'm energetic to master in computer vision
and deep learning in order to form machine vision as competent as human vision.
I have a great passion for high-tech solutions to address real-world problems with my background in
deep Learning and machine learning. In 2018, I have focused on the field computer vision as an intermediate field
because I believe that sooner or later AI will inevitably impact all aspects of our lives and industries.